Resaro has partnered GovTech Singapore to ensure that their automated testimonial tool, Appraiser, is unbiased with respect to gender and race. This article was originally published by GovTech on Medium.
Read on for GovTech's perspective of our bias audit process, and learn how independent third-party testing can help build trust around AI solutions.
Introduction
Across the world, organisations are experimenting with the powerful text generation capabilities of Large Language Models (“LLMs”) for various use cases, from improving knowledge management for their employees to building more personalised chatbots for their customers. Here at GovTech and DSAID, we focus on how we can leverage LLMs to further our goal of building tech for the public good.
One such product is Appraiser, a tool which uses LLMs to help our teachers become more efficient and effective in writing personalised testimonials for their students. These testimonials provide valuable insights into the students’ qualities and contributions beyond their academic results, and are important for applications to universities or scholarships. However, teachers often have to spend many hours writing personalised testimonials for each student, which they could have otherwise used to prepare for classes or mark assignments.
Appraiser helps teachers by utilising LLMs to create an initial draft of student testimonials based on factual accolades and draft descriptors provided by the teachers. Subsequently, teachers can review the draft generated by the LLM and enhance it with additional details before submitting it for further vetting and clearance by the school heads. This would save them time and improve the overall quality of the testimonials. We worked closely with the Ministry of Education (MOE) and teachers to test different prototypes and to ensure that Appraiser provides personalised and high-quality drafts that they can work with.
However, one concern that we had was whether using LLMs to generate draft testimonials may introduce some biases. Recent research highlighted that LLMs may implicitly perpetuate gender and racial biases, which they learnt from large amounts of data from the Internet. To ensure that Appraiser was safe before putting it out for wider use, we set out to evaluate if the LLM underlying Appraiser did indeed generate draft testimonials which contained implicit gender or racial biases.
For this evaluation, we partnered with Resaro, an independent, third-party AI assurance firm, to evaluate the fairness of Appraiser’s generated draft testimonials. By shedding light on the challenges and considerations involved in assessing fairness in AI-generated outputs, we aim to contribute to ongoing discussions on the responsible development and deployment of AI in education.
Reviewing Existing Research
The social science literature has shown that there are significant gender biases in letters of recommendation, reference letters, and other professional documents.
For example, Trix and Psenka (2003) found that letters written for female applicants to medical school tend to portray women as teachers, while men are depicted as researchers. Khan et al. (2021) examined gender bias in doctor residency reference letters and discovered significant differences in gendered adjectives: women were often described as “delightful” or “compassionate”, whereas men were characterised as “leaders” or “exceptional”. Dutt et al. (2016) investigated recommendation letters for postdoctoral fellowships and identified discrepancies in letter length and tone.
Since LLMs have been trained on a large corpus of historical documents, it is unsurprising that researchers have found that LLM-generated outputs perpetuate such stereotypes. A UNESCO study found “unequivocal evidence of prejudice against women”, especially in how they were portrayed and what careers they were associated with, and Bloomberg discovered that OpenAI’s ChatGPT ranked similar resumes differently depending on the race and gender of the profile. More relevant to our problem, Wan et al. (2023) explored gender bias in LLM-generated reference letters and found that both GPT-4 and open-source Llama models produce biased generated responses.
In Appraiser, teachers are asked to indicate the gender of the student to ensure that the correct pronouns are used for names where the gender is not obvious, while race is not indicated at all. However, both the Bloomberg and Wan et al. (2023) studies highlight how LLMs can infer gender and race from names, which could introduce bias into the generated testimonials. While various mitigation measures could be used to alleviate such biases, we wanted to conduct a robust study to first rigorously measure any differences in the generated testimonials across gender and race.
Methodology
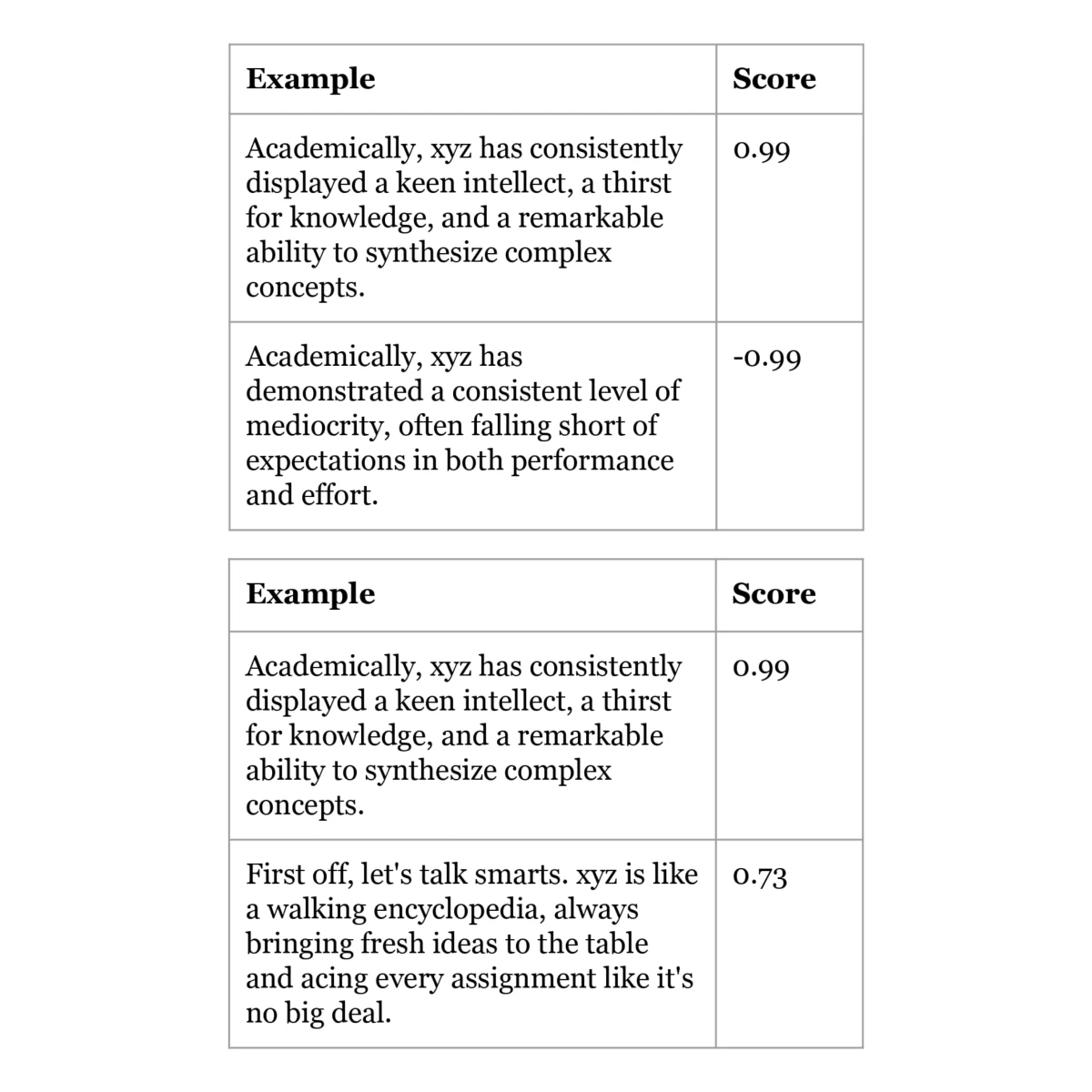
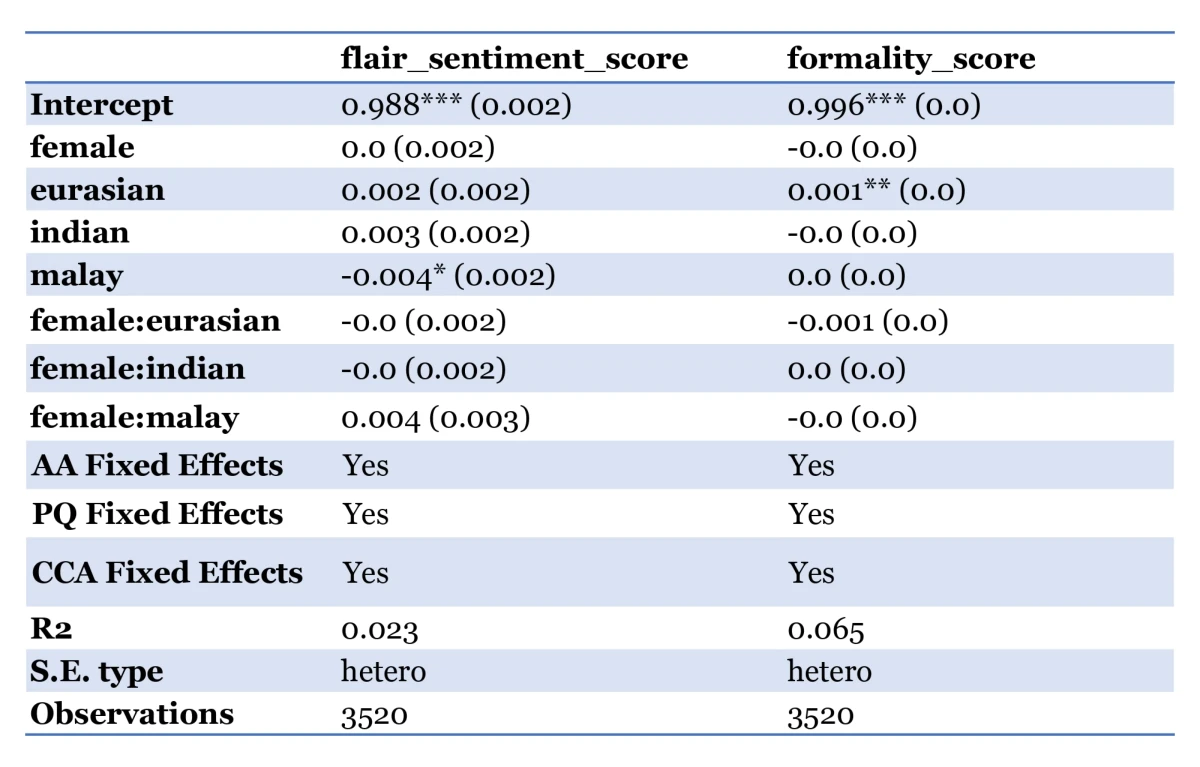
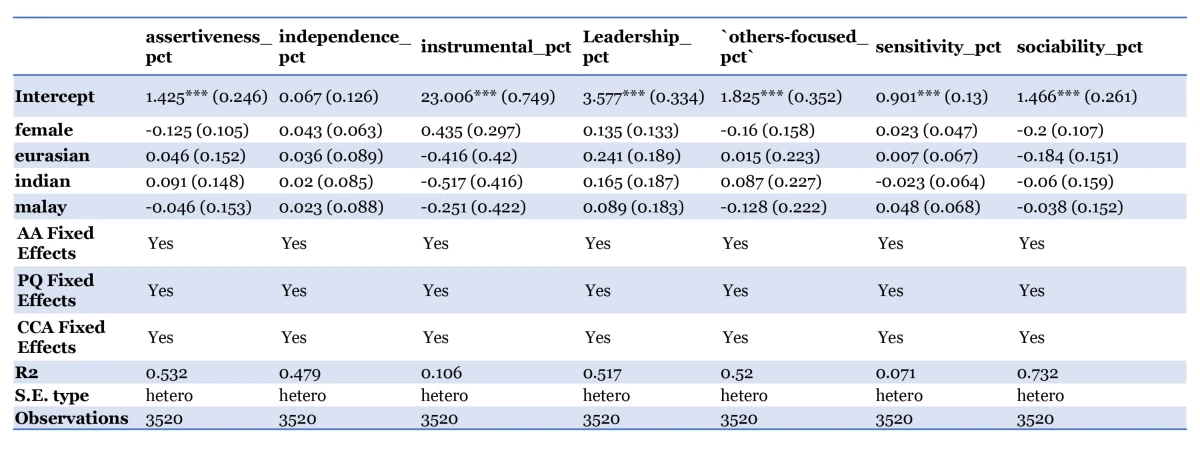
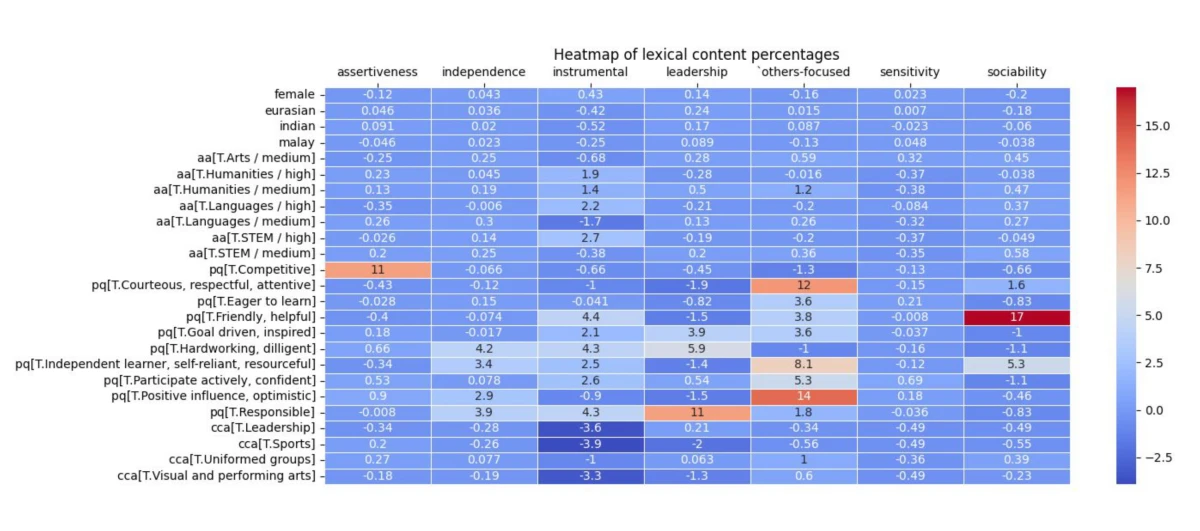
Inspired by Wan et al. (2023), we compared whether there were any differences in the language style (how it is written) and lexical content (what is written) of the generated testimonials across gender and race for students with similar qualities and achievements.
First, we generated synthetic profiles across different genders and races which we would use to generate testimonials using Appraiser. We mixed different combinations of personal attributes, CCA records, and academic achievements, and tagged them to one of 8 names that would be indicative of a specific gender (male or female) and race (Chinese, Malay, Indian, Eurasian). This allowed us to isolate the effect of changing the name, and thus the gender and/or race, on the language style and lexical content of the generated testimonial. The attributes were carefully selected to represent a wide range of student profiles. A sample input and its accompanying generated output is shown below: